In this post, I want to demonstrate why the Internet is inaccessible in Myanmar and how we can change that—with three lines of code.
Unicode isn’t universal
Before we begin, it’s crucial to understand encodings. In simple terms, an encoding system is a set of rules that a computer can follow to represent text.
Unicode is the universal standard for modern character encoding schemes. Explicitly, it promises that any computer can display and share text, no matter what platform, device, application, or language. Naturally, all of the Internet internally uses Unicode.
However, while Joe Becker, Lee Collins, and Mark Davis started developing Unicode in 1991, Myanmar was still closed off to the world after their coup in 1962. Their language, Burmese, was one of the few not included in the standard. Thus, Burmese requires a slightly different set of encoding rules, so they developed Zawgyi, the encoding system that 90% of people in Myanmar use.
The result? Many applications and websites that Myanma people use are inaccessible. On Unicode’s official website, they demonstrate how Unicode garbles Burmese text due to code point differences (Source). In the table below, they present an example of two such words. The first row displays a word ad-hoc written in Unicode, displaying incorrectly in Zawgyi with “dotted” characters. The second row displays a word correctly written in Zawgyi, but displayed incorrectly in Unicode.
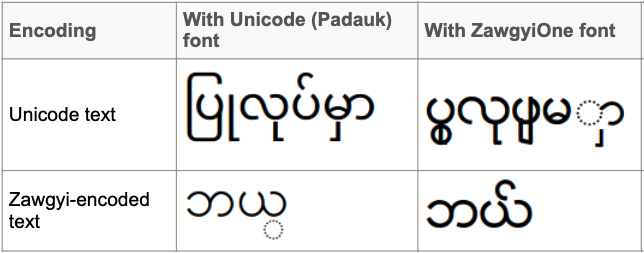
The missing step is localization.
Localization is the process of adapting internationalized software for a specific region or language by translating text and adding locale-specific components. (Source)
Why I care about this
For those who haven’t met me, first of all, hey, nice to meet you! Secondly, I’m a developer at Cal Blueprint, a student-run organization at UC Berkeley focused on building software for non-profit organizations.
Last semester, we worked with Mee Panyar, a non-profit organization that enables rural communities (primarily Myanmar, but soon Indonesia) to manage and operate solar mini-grids with targeted training and tools. Our goal was to build an offline-friendly PWA mobile application to help Myanma electricians manage and operate solar mini-grids. To accomplish this, we used ReactTS, Redux, Node, and AirTable. Read the project recap here.
Localization makes an application universal
Now, I’ll talk about the technical solution and how I arrived at it.
Problem: The Mee Panyar mobile app needs localized translation support for Burmese in Unicode and Zawgyi.
Solution: My task was to build and integrate a set of tools that would interpret a user’s device language and encoding, then perform the necessary translations and conversions to make our app feel native to the user.
Constraints: Our solution must be offline-friendly. Immediately, this means translations should be stored locally when the app builds in production. Updates to the translation database or library will reflect on the user’s end whenever they obtain this new build (e.g., an AppStore update). Thus, our initial idea of importing Google’s language API to perform translations on the fly was ruled out immediately.
Step 1: Scrape in the translation key-value store
Our NPO, Mee Panyar, maintained a key-value store (KVS) with English labels as keys and Burmese labels as values. This database can be added to and modified from their end directly. I wrote a script that pulls in the KVS locally using the AirTable API and creates two JSON objects:
- One object, stored in
./resources.js, contains the translation mapping from English to Burmese. - A second object, stored in
./words.ts, converts our English keys into a TypeScript object. You’ll see why this is useful soon.
Then, I added my script to the build command in our package.json. Now every time Mee Panyar builds their app in production, translation maps are updated and stored locally.
Step 2: Handling translations with react-i18next
I used react-i18next, “a powerful internationalization framework for React.” Out of the box, I can initialize their hook to query our resources object (If you’re new to hooks, I highly recommend reading the docs). Thus, something like
<div>{t('Hello World')}</div>
will render the text in either English (e.g., “Hello World”) or Burmese (e.g., “မင်္ဂလာပါကမ္ဘာလောက”), depending on the user’s language setting on their browser. We can detect a device’s language in TypeScript by simply calling the built-in navigator.language.
Step 3: Handling encodings with myanmar-tools
I adopted an EncodingConverter from Google’s myanmar-tools to perform encoding conversions between Unicode and Zawgyi. Thank you, Google.
Now the question is, how do we determine what encoding a device uses if all browsers internally use Unicode? The solution is to use a heuristic! To compare Zawgyi and Unicode, we can open a blank canvas, put two distinctive Burmese words on it—‘pa-sint က္က’ and ‘ka က’—and make the following decision: If the two words are equal in width, the device is in Unicode. In Zawgyi devices, the former character appears twice as long! If you’re reading this, the Burmese characters, က္က and က likely appear as a single character. The following code snippet below was taken directly from our localization toolkit.
export const detectEncoding = (): LanguageEncoding => {
const context = document.createElement('canvas').getContext('2d');
const kaWidth = context?.measureText('က').width;
const patSintWidth = context?.measureText('က္က').width;
if (kaWidth == patSintWidth) {
return LanguageEncoding.UNICODE;
} else {
return LanguageEncoding.ZAWGYI;
}
}
Step 4: Our custom internationalization hook
If you’ve never built a custom hook before, I hope this post motivates you to start. Custom hooks allow you to “extract component logic into reusable functions.” I needed to apply the following logic to every frontent component file in our codebase:
- Detect the user’s language setting.
- Determine the device’s native encoding.
- Translate between English and Burmese (and, soon, Bahasa).
- Apply conversion rules between Unicode and Zawgyi.
Rather than implementing all this logic for every file, I could instead abstract this logic into a hook by creating a function whose name starts with the keyword, use. This is React’s way of detecting a hook, which in turn allows the framework to a) isolate stateful logic (e.g., subscribing to the caller component) and b) apply React’s rules of hooks.
Here is our hook, adapted for this post.
import { useTranslation } from 'react-i18next';
import { detectEncoding } from './device';
import { EncodingConverter } from './encodings';
const converter = new EncodingConverter();
/* Custom React hook to handle language internationalization */
export const useInternationalization = () => {
const { t } = useTranslation();
const intl = (text: string) => {
switch (detectEncoding()) {
case LanguageEncoding.ZAWGYI:
return converter.unicodeToZawgyi(text);
default:
return t(text);
}
}
return intl;
}
Localization in three lines of code
Finally, the result you’ve been waiting for. To localize any .tsx or .jsx file,
- Import our hook and word bank.
import { useInternationalization } from 'lib/i18next/translator';
import words from 'lib/i18next/words';
- Initialize our hook before the JSX section of a component.
const intl = useInternationalization();
- Wrap any text in the hook, then replace the argument with the corresponding key in the word bank.
intl(words.customers); // -> "Customers" or "ဖောက်သည်များ"
If your code editor has IntelliSense, you can take advantage of the code completion feature when referencing our word map!

Our hook not only translates text but also encodes it based on the user’s device. The result is an application that looks and feels native and accessible to users in Myanmar.
Abstraction is beautiful
If there’s one lesson you can take away from this post, it’s the importance and beauty of abstraction.
With our custom internationalization hook, we’ve not only abstracted complexity away from our end-users, but also for future developers that we’ve passed the project onto (hi Trevor!). This way, developers can focus on core application logic in English without worrying about language barriers.
In addition to building translation tools this past semester, I also took CS 162, Berkeley’s course on Operating Systems. I learned that modern operating systems are illusionists! They rely on building blocks at the atomic level (e.g., threads and processes) to build systems at the molecular level (e.g., kernels) to build workflows at the optical level (e.g., scheduling) and beyond! The modern operating system enables developers to focus on building more complex workflows without constantly worrying about low-level details.
We should proceed with caution as we can’t (or shouldn’t) abstract away everything. But for now, I can confidently say that these experiences have shown me that abstractions are at the crux of computer science.
.
This is my first blog post ever, so any feedback is greatly appreciated! Tell me what you loved, hated, found intruiging, found boring, etc.