As I cross my one-year anniversary as a software engineer, I reflect back on the industry I operate in and the lessons I’ve learned.
The following graph depicts the Gartner hype cycle :

Marketers and tech reporters can refer to this diagram to illustrate how a disruptive technology matures and adopts over time. For autonomous vehicles, I’d paint the following picture:
-
Innovation trigger - “A potential technology breakthrough kicks things off”. In October 2005, DARPA hosted a 7.32 mile race for autonomous vehicles through Beer Bottle Pass in Nevada. Here, we revel the epic story of how Stanford’s Racing Team with Professor Thrun and CMU’s “Red Team” with Professor Whittaker built autonomous vehicles that completed the rugged course… in ~7 hours. How anticlimactic. However, this was a huge achievement for its time and marked early beginnings for driverless vehicles.
-
Peak of inflated expectations - “Early publicity produces a number of success stories”. In high school, I remember reading news articles where companies like Uber, Nissan, Ford, and Tesla promised to deploy fully autonomous vehicles on city roads between 2017 and 2020. At this point, the market was bullish on AVs. Between 2010 - 2022, investors have poured $160 billion dollars into autonomous transport.
-
Trough of disillusionment - “Interest wanes as experiments and implementations fail to deliver”. In 2021, I took a course on artificial intelligence and one of the opening slides to the topic of reinforcement learning was a Tesla crashing, killing two passengers in Texas. This was a sobering reminder that “we’re not there yet” when it comes to autonomous systems.
-
Slope of enlightenment - “More instances of how the technology can benefit the enterprise start to crystallize and become more widely understood”. As of two weeks ago, Cruise and Waymo operate in the SF Bay Area. Last Friday, I took a Cruise from Hayes Valley to Dogpatch. The car’s name is “Mandolin”, and she did a great job. She navigated around double-parked cars, made effortless unprotected left turns, and played soothing elevator music. The ride was boring, yet exhilarating.
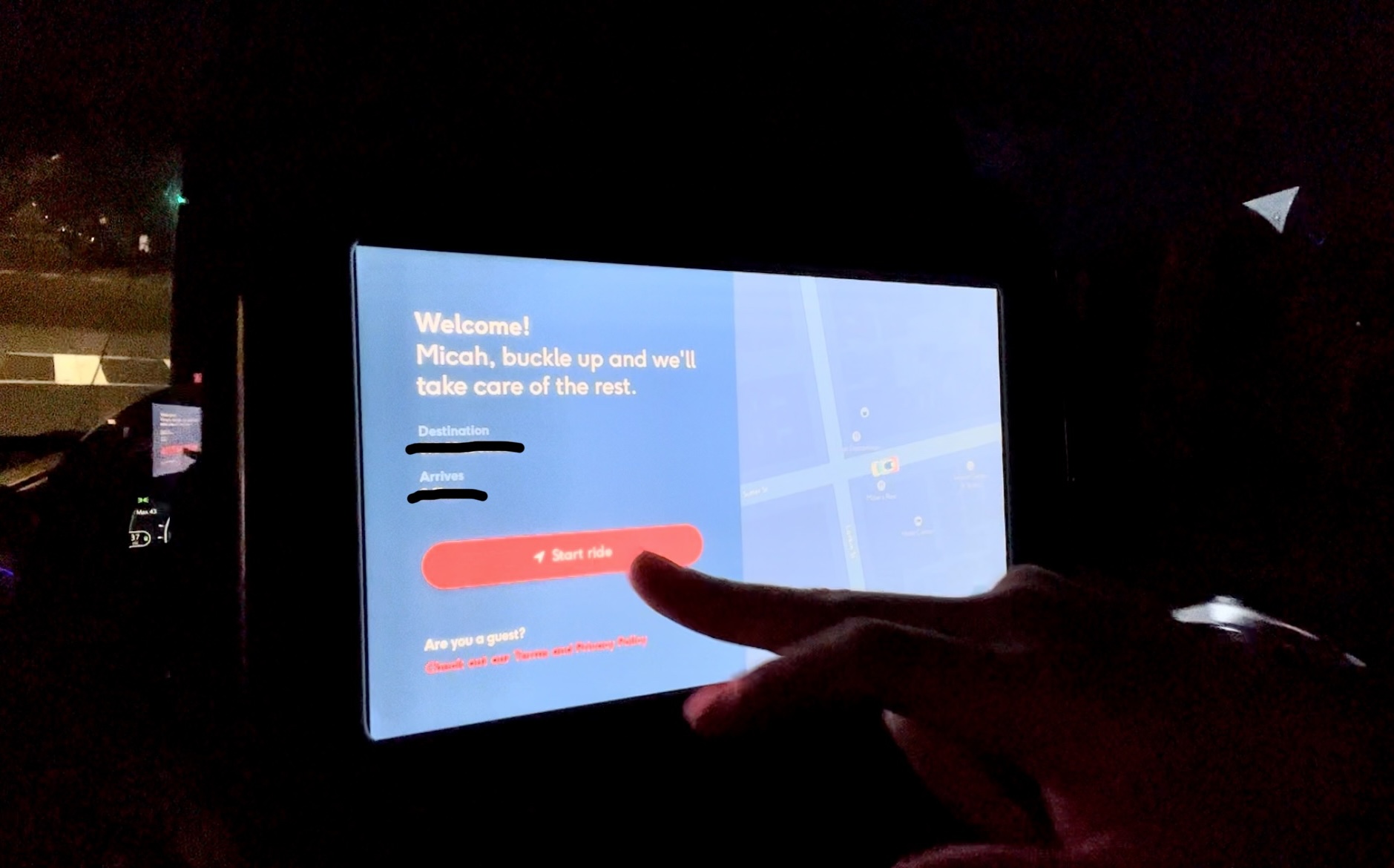 Interactive prompt to start and track my driverless taxi ride.
Interactive prompt to start and track my driverless taxi ride.
- Plateau of productivity - “Mainstream adoption starts to take off”. To get here, I think L2-L4 capabilities need to be widely accessible in the general market. Major OEMs need to catch up to the Teslas, Cruises, and Waymos of the world before thinking about cost-cutting, lowering risks, and other activities in the productivity plateau phase. This effort is part of what I’ve been up to for the past year! At Applied, our mission is to accelerate the world’s adoption of safe and intelligent machines.
…
When reading about the Gartner hype cycle, I thought about how it related to my expectations for impact and quality for my early career (y-axis).
Looking back at the past year:
-
Innovation trigger. In the half-hour leading up to my interview, I remember re-reading my Leetcode study sheet several times. In the seconds before joining the Google Meet, I took deep breaths. Ready to join? Jack is in the call. I had 40 minutes to implement the backend of a logic puzzle game. My interviewer, Jack, was friendly, yet laser-focused. He nodded his head when I explained a reasonable approach and probed with precise questions when he saw gaps in my implementation. With luck, I passed the interview.
-
Peak of inflated expectations. Eight days later, I get a notification on my phone. Micah, we are pleased to offer you the position of Software Engineer… After getting off the phone with my recruiter, I click the link. Virtual confetti rains down my screen. I was so ecstatic that I recorded myself accepting the offer letter and dapping up the camera. I’m on a mission to rebuilt city infrastructure with autonomous vehicles and its gonna be awesome. In my mind, I’m already thinking about all the ways I could leverage my experience in distributed systems and web development to build ~ data-intensive applications ~ for the vehicle software space.
-
Trough of disillusionment. One of the worst feelings in the world is when someone else finds a bug I caused. Many infra engineers have some experience where they accidentally caused a production outage (e.g., site is down, critical service is not picking up new messages, etc.) for a customer—I am one of them. In my first few months, I learned the hard way that the systems I work on, while powerful and useful, are complex and interconnected. In these moments, my mind clouds with doubtful thoughts, This will be much harder than I thought. Am I prepared for this? Will I be useful?
-
Slope of enlightenment. Where I am today. It’s that feeling of alignment between you, your manager, your PM, and customers—that your work was, is, or will likely be measurably impactful for users. It’s that feeling of trust from your team and your manager, where they know that, with the right support, you are going to ship what you say you’re going to ship. Your opinion for engineering design and product direction matters.
…
One of the main criticisms of the hype cycle was that it offered “no actionable insight for moving a technology to the next phase” (source). In this section, I want to share some of my learnings on how I moved from the trough of disillusionment into the slope of enlightenment as a first-year SWE.
Disclaimer: The following section is a reflection of my experience and the stage of my company. We’re in a high-growth stage, where we have customers that rely on our products every day (literally). Our ability to plan strategically and delegate are more critical and sustainable for growth than “moving fast and breaking things”.
Don’t beat yourself up over your mistakes, but take ownership over the solution
An experienced software engineer should, as much as possible, think through all the edge cases and be paranoid about their code before shipping it to customers. However, as a new engineer in a startup, it’s almost inevitable that you’ll make mistakes that make it in production.
In my first release at Applied, I caused a regression where users couldn’t see some of the simulation results in their search query. A customer caught this in the morning and I pushed a fix and deployed a patch before lunch time. Even with such a quick fix, I couldn’t help but feel low: how was I so careless? why did I not catch this?
My manager noticed this and later gave me feedback. My takeaways:
- Don’t beat yourself up. It’s unfortunate that a customer caught a bug, but it’s also the team’s responsibility (e.g., reviewers, QA team) to ensure we catch and squash bugs before they make it to prod, not just the individual. Continually putting yourself down doesn’t help anyone at this point. Instead…
- Own the solution going forward. Tactically, I 1) added unit tests to ensure the query’s correctness and 2) created a manual test case for our QA team to ensure that, end-to-end, results return correctly. Behaviorally, I spent more time thinking through edge cases when drafting engineering designs rather than immediately jumping in to push code. After pushing code, I would manually test those edge cases.
As a result, I pushed fewer bugs. Even when a bug did come up, I didn’t dwell on the mistake for too long. The immediate response is: Grr. Ok. Let’s patch this ASAP, then brainstorm how we’re going to prevent this failure mode from ever happening again.
Leave systems better than you found them (going above and beyond in your work)
My team owns a platform to search/analyze simulation results. Overtime, power users (e.g., customers running hundreds of thousands of simulations per week) noticed that the platform didn’t scale well. Some users reported core pages taking minutes to load. Have you ever waited minutes for your favorite app to load? At my company, this symptom clearly broke service-level agreements (SLA).
Each release cycle spans five weeks. For three releases straight, I worked on query performance optimizations for these pages. Together, we brought down P95 loading times from the order of minutes to less than five seconds. Our team quickly became “experts” in query performance.
Naturally, a few questions came up from other teams:
- How did you do that? Or, translation: how can we replicate these results across our pages?
- How did you find which queries were slow?
- Our team queries the database using GraphQL, not raw SQL. How do we translate our query to SQL?
- How will you ensure these queries don’t regress again?
For the next release, we built out or improved the following tools:
I spent the next release building general tools for finding, debugging, optimizing, and load testing GraphQL queries to ensure they stay under X seconds, forever. Some examples:
- A query monitoring dashboard that could determine, in realtime and on any cluster, what the most expensive queries were—broken down by P95 latency and queries per second.
- An internal tool that converts GraphQL, a query language for APIs, to SQL, a declarative language to store, retrieve, or manipulate data in your database. Then, you can use PostgreSQL’s built-in EXPLAIN-ANALYZE tool for analyzing the SQL query plan.
- A load-testing CI pipeline using K6, which lets you execute queries against a cloud cluster at scale. I love K6 not only because it reports P95 latencies and data quantity received, but it also lets you specify pass/fail conditions (called thresholds) for those metrics (e.g., P95 max).
We built this project at a time where performance and stability was top of mind for our company. As a result, this was a culmination of one of my most valuable contributions in the past year.
Create a culture of transparency with your manager
The first learning was about having the right mindset, to expect failures and to grow from them. The second learning was about going the extra 15%, to build tools and systems that, essentially, codify your expertise. Perhaps the most important learning, one that’s harder to control, is to establish a culture of transparency with your manager.
In my second week in my job, my manager told me I was moving too slowly. She told me I could reach out for help sooner and should code faster. I was taken aback at first, but I learned to appreciate this type of constructive feedback. Constructive feedback keeps my expectations for my work grounded. I would much rather her tell me straight up rather than an entire team quietly thinking that I drag them down.
And it wasn’t just the fact that she gave feedback, it was the way she gave feedback.
At my company, we read Kim Scott’s Radical Candor. The book covers a technique called the COIN method, a model for giving critical feedback. For the above example:
- C := Context. “Hey Micah, I noticed that you spent almost the entire day investigating an issue that should’ve taken half a day to complete.”
- O := Observation. “I noticed you put your headphones in and didn’t ask for help. However, when I asked you about the root cause later that day, you didn’t seem sure of your response and it turns out you were looking at the wrong thing.”
- I := Impact. This instance represents an opportunity cost in terms of lost engineering time.
- N := Next steps. That day, I learned about the “15-minute rule”—in the first few weeks as a new hire, we should spend around 15 minutes struggling to understand an issue before asking for help. Past 15 minutes of struggling on an issue with no progress, I learned to definitely ask for help.
Of course, feedback is a two-way street. One time, we had a team meeting reflecting on the most recent release. We went over highlights, like all the positive shoutouts from the performance work we’ve been doing. We also went over lowlights, like implementing a feature that a customer asks for without digging at the problem deeper. As I read the lowlight on the slide, I think to myself, huh, that’s interesting, I wonder what she’s referring to. Then, she gestures towards me and explains how my work wasn’t solving the customer’s true problem. Woah, what just happened. My work? I was in shock. I didn’t want to detract from the meeting, so I nodded and waited until the meeting ended to confront her.
Long story short, she was right about us not solving the right problem. However, I wasn’t included in the related user-discovery conversations or debriefs that led to this conclusion. That’s why I was taken aback during the meeting.
After this conversation, several things happened:
- Before each release, we go through the features each person will work on and say out loud 1) how it will impact X customers and 2) how it fits into our longer term product roadmap.
- Engineers on my team are encouraged to lead user discovery meetings, attend feedback sessions, and inform product direction for each release.
Ultimately, my manager and I created a relationship where it feels natural to give each other direct feedback as soon as we see something to help ourselves and the team improve.
Conclusion
Writing this post made me realize that I’ve learned so much this past year. There were a few other topics that I wanted to cover such as: why I value storytelling, when to leverage usage metrics in a your product, how we broke (and fixed) prod for all customers in a day, etc. I’ll save these stories for another time.